
Upstream: Building Conviction Through Better Questions
Conviction in primary research comes from better questions. This article breaks down why up to 40% of expert calls fail to move investment decisions, how poor question design destroys value upstream, and the exact framework top investors use.

✦
Conviction flows downstream. By the time an analyst sits on a call, writes up notes, and presents findings to the investment committee, the quality of the output has already been determined. The expert was fine. The transcript looks professional. But the research produces nothing that moves the position. The problem started upstream, at the source, long before anyone picked up the phone. Roughly 40% of expert calls produce nothing useful, and the reason is almost never the expert. The reason is that the questions were never tied to a decision. Most teams treat question design as a formality before the real work begins. The best teams understand that question design is the real work. Everything else flows from it. Research that builds conviction starts at the source.
Why research breaks
According to Bain & Company's 2020 Global Corporate M&A Report, almost 60% of executives attributed deal failure to poor due diligence that did not identify critical issues. McKinsey research found that 42% of the time, pre-merger due diligence fails to provide an adequate roadmap for capturing value. The pattern is consistent: research breaks not because analysts lack effort, but because the questions were never tied to decisions that matter.
The failure mode is almost always the same. Teams design questions for coverage instead of decisions. They want to "understand the market" or "get a sense of competitive dynamics." These goals are fine as starting points. They fall apart as endpoints. They produce transcripts that read well but never answer the question that matters: should we change our position?
Research breaks when there is no explicit link between what gets asked and what would be done differently if the answer surprised everyone.
Most question guides are 50% longer than they need to be. Analysts include questions because they feel relevant or interesting, not because the answers would change anything. The result is calls that generate colour without conviction, transcripts that sit in folders without informing models, and research budgets that deliver coverage reports instead of investment edge.
The fix requires going upstream. Working backward from decisions rather than forward from topics. Every question earns its place by moving a variable that matters. If no one can articulate how a surprising answer would change sizing or direction, the question does not belong in the guide.
"Coverage questions produce transcripts. Thesis questions produce conviction."
Start at the source
Every question earns its place by moving a decision. Start from the investment memo. Work backward to the source.
Define the decision first. What variable needs to move? Size up, hold, or exit? 20% IRR or pass? If the decision cannot be articulated in a single sentence, the team has not yet reached the source. Most research plans skip this step entirely. They begin with a topic and hope that talking to enough people will produce clarity. That approach works occasionally. It fails expensively more often.
Write two to three explicit hypotheses. Churn is structurally below 5%. Price increases will stick. The new competitor is taking 10 to 15% of mid-market share. These are not hunches. These are testable claims that the thesis depends on. Writing them down forces precision. Vague hypotheses produce vague questions. Vague questions produce vague answers. Pollution at the source contaminates everything downstream.
A good question is one where a different answer would change sizing or direction. If the answer would not alter the memo, cut the question. This is the hardest discipline in primary research. Most analysts include questions because they are interesting, not because they are decision-relevant. Interesting questions create a sense of productivity. Decision-relevant questions build conviction.
The test is simple. Imagine the expert gives a surprising answer. Does it change anything? If the response would be a shrug, the question does not belong in the guide. Run this test on every question before making the first call. More will get cut than expected.
Breaking hypotheses into signals
Map each hypothesis to concrete, observable signals. This is where vague research plans become specific.
Volume and mix signals include order trends, pipeline shape, cohort behavior, and implementation timelines. These reveal whether demand is real and sustainable or whether headline growth masks underlying weakness.
Price and margin signals include list versus realized pricing, discounting behavior, elasticity, and input costs. These reveal whether the company can hold or expand margins as it scales, or whether competitive pressure is eroding pricing power beneath the surface.
Share and competition signals include win rates, head-to-head battles, and switching patterns. These reveal whether the competitive moat is real and whether new entrants pose a genuine threat.
Execution risk signals include implementation failures, churn drivers, salesforce quality, and product gaps. These reveal whether the company can deliver on its promises and whether operational weaknesses will surface post-close.
Each signal gets one question that forces specificity. Numbers. Ranges. Recent examples. Behavior.
"Walk me through a recent deal" beats "How is demand?" The first anchors reality. The second invites a prepared talking point. Experts are often eager to share opinions. The interviewer's job is to make them share facts.
The difference between a useful call and a wasted call is almost always the difference between questions that demand specificity and questions that allow generalities. Generalities feel informative in the moment. They evaporate when someone tries to use them in a model.
"Measurable signals are facts. Everything else is noise."
Facts first, opinions second
The sequence matters. Facts, then interpretation, then prediction. Always in that order.
Start with "show me" questions. In the last three to six months, what happened to average monthly spend with this vendor? How many serious competitors appear in RFPs, and which ones? What percentage of customers in this patch renewed last cycle?
These questions force the expert to anchor in direct experience. They cannot answer from headlines or hearsay. They have to recall actual events. This is where primary research creates information that does not exist anywhere else. Documents reveal what companies say. Experts reveal what actually happened.
Layer in "why" and "so what" only after establishing the factual baseline. What were the top two to three reasons the last customer who left switched? What would make this customer pay more for the product? These interpretive questions matter, but they only produce useful answers when grounded in specific facts.
Opinion questions survive only if they map to risk or edge. Key-man risk. Culture. Execution quality. Otherwise, cut them. Opinions feel valuable in the moment. They rarely survive the transition from transcript to model. An expert's opinion about where the market is heading is speculation. Their account of what happened in their last three deals is data.
Facts anchor reality. Opinions matter when they illuminate risk. Predictions are useful only after the first two are established.
Making questions investment-grade
Good questions are neutral. "How has churn changed?" Not "Churn is low, right?" The second embeds a conclusion. It signals what the interviewer wants to hear. Experts are human. They pick up on cues. Biased questions produce biased answers. The goal is truth, not validation. Questions should surface bad news as easily as good news.
Use concrete time frames. Last quarter. Last 12 months. Since the new product launched. Vague time frames produce vague answers. Specific time frames force the expert to recall specific events.
Use specific cohorts. Top 10 customers. Mid-market accounts. Customers who joined in the last 18 months. Aggregate questions produce aggregate answers. Cohort-specific questions reveal the variation that matters.
Mix quantitative and qualitative. Ranges, percentages, counts, examples, narratives. Numbers without context are dangerous. Context without numbers is soft. Both are needed to build conviction.
Run three checks on every question before it goes into the guide.
First, would a strong answer change position sizing or thesis? If the answer is no, the question is filler. It might be interesting. It might feel relevant. But if it would not change anything, it does not earn a place in the guide.
Second, can an honest expert answer from experience rather than guesses? If the question asks about things outside their direct knowledge, the invitation is for speculation. Speculation feels like insight. It is not.
Third, is the question free of embedded conclusions or bias? If the question telegraphs what the interviewer wants to hear, rewrite it. Experts want to be helpful. They will often give what they think someone is looking for. The interviewer's job is to make it impossible for them to know what that is.
Rewrite or cut anything that fails these checks. Most question guides are 50% longer than they need to be because analysts include questions that feel relevant but do not pass.
"Investment-grade questions pass all three checks. Everything else is filler."
Structure follows your memo
Expert calls and qualitative work should follow a funnel structure.
Open broad to surface unknowns. "Walk me through how purchasing decisions for this product are made in your organization." This gives the expert room to tell you things you did not know to ask about. The best insights often come early, before the expert settles into answering your specific questions.
Move into structured blocks tied to your memo. Demand. Pricing. Competition. Product. Risk. Each block maps to a section of your investment thesis. This is not a script. Good interviews follow threads. But the guide keeps you tied to the memo when experts go off track.
Close with stress tests and outliers. "What would need to happen for you to materially cut spend or switch?" These questions reveal edge cases and tail risks. They force the expert to think about scenarios rather than just describe the status quo.
Surveys follow different logic. Start with tight screeners. Only the right personas get through. Role, budget authority, product usage, region. Build a spine of quantitative questions for comparability. Likert scales, ranges, multiple-choice. Add targeted open-ends where nuance matters. But never more than two or three open-ends. Respondents stop trying after that.
Structure follows the memo
Expert calls and qualitative work should follow a funnel structure that maps to the investment thesis.
Open broad to surface unknowns. "Walk me through how purchasing decisions for this product are made in your organization." This gives the expert room to share things the interviewer did not know to ask about. The best insights often come early, before the expert settles into answering specific questions. Experts know things that researchers do not know they need. Broad opening questions create space for those things to surface.
Move into structured blocks tied to the memo. Demand. Pricing. Competition. Product. Risk. Each block maps to a section of the investment thesis. Good interviews follow threads. But the guide keeps the conversation tied to the memo when experts go off track. Some experts love to talk. Without structure, 40 minutes will go to interesting tangents and five minutes will go to the questions that matter.
Close with stress tests and outliers. "What would need to happen for you to materially cut spend or switch?" These questions reveal edge cases and tail risks. They force the expert to think about scenarios rather than just describe the status quo. The status quo is what documents reveal. Scenarios are what experts are for.
Surveys follow different logic. Start with tight screeners. Only the right personas get through. Role, budget authority, product usage, region. A survey of the wrong people is worse than no survey at all. It produces data that looks rigorous but reflects the wrong population.
Build a spine of quantitative questions for comparability. Likert scales, ranges, multiple-choice. These create the structure that allows aggregation and comparison across respondents.
Add targeted open-ends where nuance matters. But never more than two or three open-ends. Respondents stop trying after that. Survey fatigue is real. Long open-ended questions at the end of a survey get one-word answers or nothing at all.
Map every question to the model
Each question maps to a cell in the model. If no one can point to where the answer goes, the question does not belong in the guide.
This question feeds churn assumptions. These three inform pricing power and gross margin. This block maps to TAM penetration and growth runway. The exercise of mapping questions to model cells is uncomfortable. It reveals how much of most research plans is coverage for coverage's sake.
A question with no clear destination in the model is filler. A question that tightens a range or changes a key assumption builds conviction. The former creates a sense of productivity. The latter makes money.
Build a simple table before any research project. Left column: the question. Right column: the model cell or assumption it informs. If the right column cannot be filled in, delete the question from the left column.
This discipline is painful the first few times. It forces acknowledgment that many questions exist because they feel relevant, not because they connect to anything. Over time, it becomes second nature. Questions get written with their model destination in mind. Guides get shorter. Calls get more useful. Conviction gets stronger.
"If the answer does not touch the model, delete the question."
What this looks like in practice
A SaaS acquisition that Woozle worked on illustrated the pattern clearly. The PE buyer had solid headline metrics. Strong ARR growth. Low logo churn. Expanding ACVs. Expert network calls had delivered positive takes that endorsed the management story.
The question was simple. Is the buyer overpaying if they lean into this NRR story?
The research plan focused on three levers. Churn. Expansion. Pricing power. Customer surveys ran across multiple cohorts. Interviews covered current customers, lost customers, and key partners. Channel and competitor checks included implementation partners and former sales leaders.
Every datapoint got fact-checked for role and relevance. Responses got tested for internal consistency and against external SaaS benchmarks. The goal was to stress-test the thesis, not confirm it.
The pattern that previous expert calls missed: logo churn was technically true but economically misleading.
Churn was back-loaded and concentrated. Overall annual logo churn matched the reported figure. But smaller and mid-market cohorts were churning or materially downgrading after 18 to 24 months at rates higher than management disclosed. The number in the deck was accurate. The story it told was not. Headline churn of 8% masked mid-market churn of 15% and SMB churn above 20%.
Net expansion was flattered by large accounts. A handful of enterprise customers with significant upsell masked stagnant or shrinking spend in the long tail. True NRR adjusted for customer size and tenure was 5 to 10 points lower than the headline figure. Management was presenting the number that looked best. The job was to find the number that was true.
Pricing power was weaker than pitched. Customers reported heavy discounting on renewal and aggressive offers from newer SaaS competitors. The sticker price was holding. The realized price was eroding. List price increases of 5 to 7% annually were being offset by 10 to 15% renewal discounts that did not appear in the investor materials.
Traditional expert calls missed this. They skewed toward friendly references and ex-insiders who had equity incentives to talk up the company. They produced anecdotes that sounded good but never became cohort analysis.
Findings got translated into the model. Forward ARR growth assumptions came down by several points. Sustainable net retention rate got reset down 5 to 10 percentage points. Terminal value assumptions got adjusted to reflect weaker pricing power. The buyer moved from the higher end of their target ARR multiple band to the middle.
The result was a 15% reduction in valuation.
The difference was not better experts. It was better questions. Questions designed upstream, at the source, before the first call. Questions that forced specificity instead of inviting generalities. Questions that mapped directly to the cells in the model that determined price.
"Good questions turned anecdotes into cohort analysis. Moved valuation 15%."
What bad questions actually cost
Funds see the vendor invoice. They miss the hidden tax.
Typical analyst all-in cost runs $200,000 to $400,000 per year. Salary, bonus, benefits, seat, data, overhead. At 2,000 working hours per year, that works out to $100 to $200 per hour fully loaded.
Consider a simple expert network project with five calls. The analyst spends roughly 4.5 hours per call. Defining the brief. Coordinating with the network. Scheduling. Sitting on the call. Writing notes. Extracting key points. Summarizing for the PM.
Five calls equals 22.5 hours of analyst time. At $100 to $200 per hour, the analyst time on one $6,000 project is $2,250 to $4,500.
Add vendor fees of $6,000. Total cost: $8,250 to $10,500.
But 40% of calls are useless or off-target. Only three of five calls materially move the thesis. The other two produce nothing that changes the view.
Cost per useful call: $2,750 to $3,500.
Those 22.5 hours could have gone to deeper modeling. Wider watchlist coverage. Better work with PMs and risk. More thorough review of the next opportunity. The opportunity cost is invisible but real.
Funds say "It's $1,200 a call." The truth is closer to $2,500 to $3,500 per useful insight when team time and the 40% failure rate get included. Bad questions do not just waste money. They contaminate everything downstream.
The true cost of an expert call: vendor fees are just the beginning. Analyst time and the 40% failure rate push the real cost per useful insight to $2,500 to $3,500.
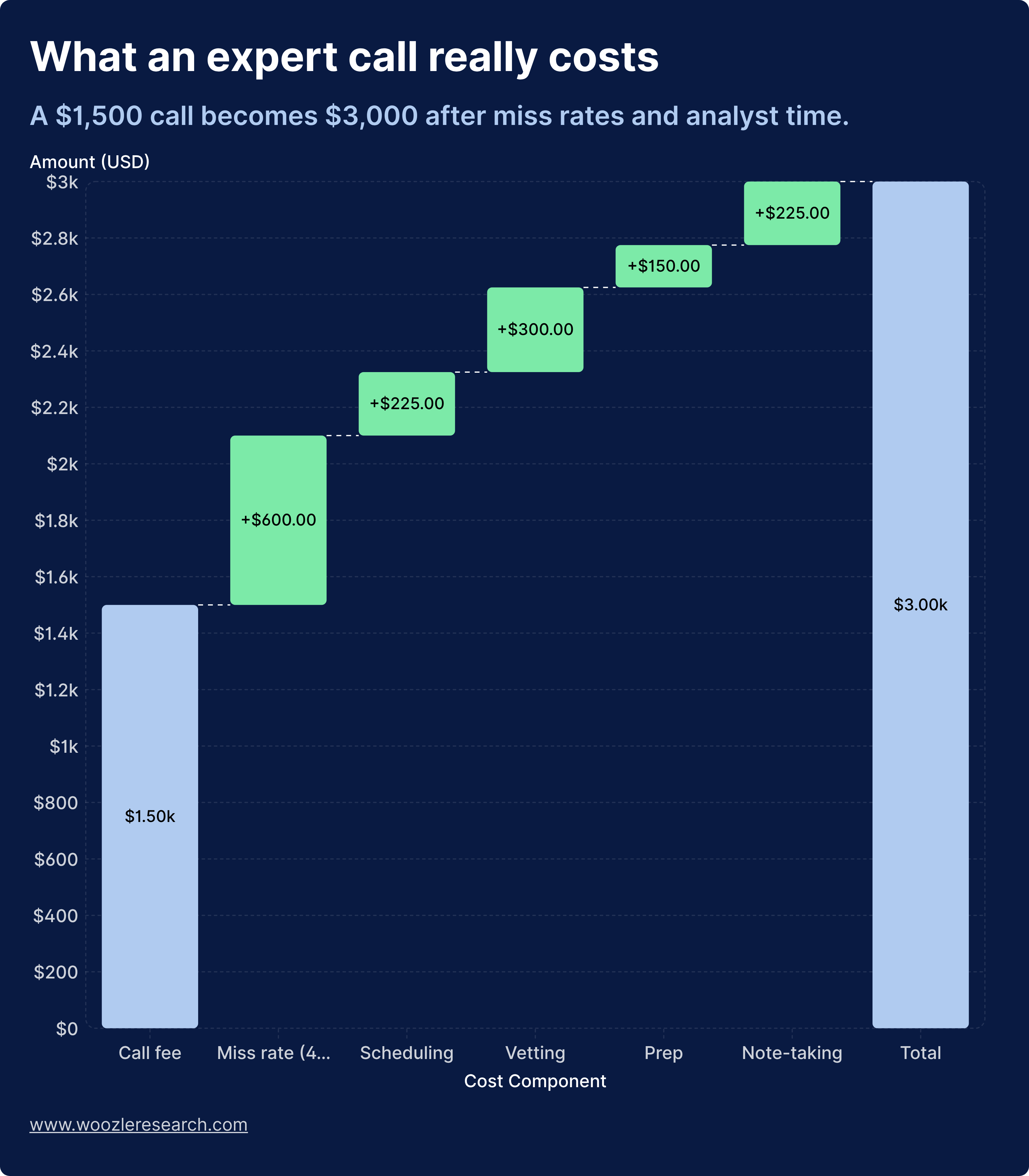
"The truth is closer to $2,500 to $3,500 per useful insight when team time and the 40% failure rate get included."
Where AI stops and research starts
AI processes information. Primary research creates it.
Three things AI cannot replicate.
Getting people to say what they think. High-stakes experts and operators do not talk the way documents read. Getting past PR-safe answers requires reading the room, adjusting tone, pushing on contradictions, and knowing when silence does the work. An algorithm cannot build rapport. It cannot sense hesitation. It cannot follow a thread that the expert did not know they were offering. The most valuable moments in expert calls are often the pauses, the hedges, the moments where the expert is deciding whether to tell the real story. Recognizing and navigating those moments is human work.
Interpreting messy reality. Operators disagree. They misremember. They contradict each other. Sometimes they lie. Turning that into an investment view means judging who to weight, which anecdote is an outlier, and when a contradiction is the signal rather than the noise. This requires judgment that cannot be reduced to pattern matching.
Deciding what is investment-grade. The hard part of primary research is not asking or transcribing. The hard part is deciding, with accountability, "This is solid enough to change a position." That decision requires ownership. A human has to stand behind it. When the call is wrong and the position loses money, someone has to explain why they believed what they believed. That accountability cannot be delegated to a model.
AI will consume document review, pattern recognition, and mechanical analysis of existing data. It will not replace the human work of persuading the right people to share what they know, interrogating them in real time, and judging what is true, what matters, and what should move capital.
Closing thoughts
Conviction flows downstream. The quality of the research, the usefulness of the calls, the strength of the conclusions, all of it is determined upstream, at the source, before anyone picks up the phone.
The framework is simple. Start from the decision, not the topic. Write explicit hypotheses. Map each hypothesis to measurable signals. Ask for facts first, opinions second. Make every question pass three checks. Map every answer to a cell in the model.
The 40% of calls that produce nothing useful share a common pattern. The questions were designed for coverage, not conviction. They were interesting but not decision-relevant. They invited generalities instead of demanding specificity. The problem was not downstream. The problem was at the source.
That outcome is avoidable. Treat question design as the foundation that determines whether the rest of the work produces anything useful. The best analysts spend more time on their question guide than they do on the calls themselves. They know that a tight question, asked of the right expert, builds more conviction than ten calls built on vague curiosity.
Bad questions cost $2,500 to $3,500 per useless insight. Good questions turn anecdotes into cohort analysis and move valuations by double digits. The difference between them is determined upstream.
Conviction starts at the source.



